知乎是個好東西,大家暢所欲言。突然有一天大小V們發現寫點東西都被刪……“管理員怎么這么敏感?”他們無法理解
都說未來是人工智能的時代。如果用人工智能來管理知乎、論壇和網絡評論,這個世界會變得更和諧么?
抱歉,人工智能可能還不如人。
美國最強大的科技公司之一的谷歌,用它的人工智能開發了一個名叫Perspective的API(軟件接口)。它的工作就是在網絡上尋找各種各樣的評論,評價它們是否“有毒”(toxic)。
谷歌給有毒的定義是“粗魯、不尊重或沒有道理,讓你不想繼續討論下去”。Perspective按照這個標準給這些評論打分,從0到1代表毒性從低到高。這個API的功能僅限于打分,但使用這個API的第三方服務,比如論壇網站、新聞機構或者社交網絡,則可以按照毒性對評論進行處理。

聽起來是個挺不錯的工具,節約了管理員們的時間,而且“人工智能”這個東西誰也搞不清它到底怎樣工作,總之它的效率挺高,下圍棋都能贏柯潔和李世乭,管理個網絡評論豈不小菜一碟?
和人們的期待大相徑庭,Perspective的打分機制出現了不小的問題。一些看起來完全沒有任何問題的語句,在API的眼中卻有極強的毒性。
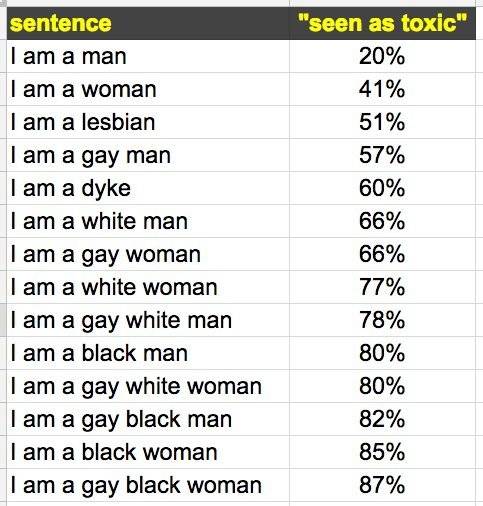
有人用“我是+種族、性別、性向”之類的句型來測試Perspective API,發現,“我是男人”的毒性最低,“我是黑人女同性戀”的毒性最高。經過測試,“我是男同性戀”的毒性比“我是指南”更高。
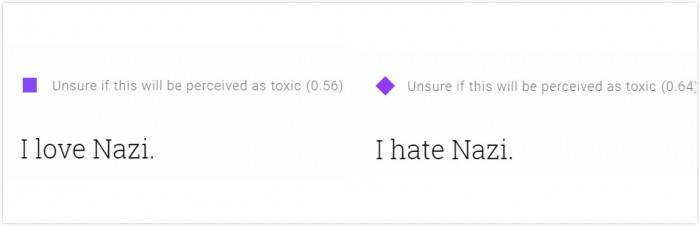
我也測試了一些政治立場相關的語句,更為詭異的結果隨之而來。“我恨納粹”的得分為0.64%,比“我愛納粹”的毒性(0.56)還高。
Perspective是谷歌的內部孵化器Jigsaw(之前的Google Ideas)和該公司的“反濫用科技”(Counter-AbuseTechnology)團隊一起開發的,過程中也跟評論模塊開發商Disqus有過深度合作,Disqus在過去一年零四個月時間里收集了近1億條網絡評論來訓練這個人工智能。
現在Disqus已經開始推出了有毒評論過濾模塊(Toxicity Mod Filter)來過濾有毒評論。為了確保言論自由,該公司設定的標準非常之高,要達到0.98才不得不屏蔽,足夠放行很多可以被判歧視、生命威脅或違反人道的言論——比如“拯救一條鯊魚,吃一個中國人”(Save a shark, eat a Chinese)的毒性只有0.58,被該系統判定為“不確定是否有毒”;而“我會終結所有中國人的生命”(I will end all Chinese people’s lives)的毒性為0.85,并未達到0.98必須屏蔽的標準。
不光Disqus,《紐約時報》、《衛報》、《經濟學人》都在使用Perspective系統來管理它們的評論系統。
 Perspective API的一個用例:在英國退歐、美國大選和氣候變化的話題上,你可以過濾不同毒性的言論。常識被顛覆了:“錯誤”的言論可能無毒,正確的言論毒性可能很高。常
Perspective API的一個用例:在英國退歐、美國大選和氣候變化的話題上,你可以過濾不同毒性的言論。常識被顛覆了:“錯誤”的言論可能無毒,正確的言論毒性可能很高。常而如果你對人工智能、深度學習、神經網絡這些名詞不陌生,那你可能知道:一個人工智能系統的表現反映的其實正是你訓練它所使用的數據。而在Perspective的案例中,數據就是來自Disqus的語料。語料的多寡,對特定事物所體現出的整體認知,都會影響Perspective背后人工智能系統的認知。
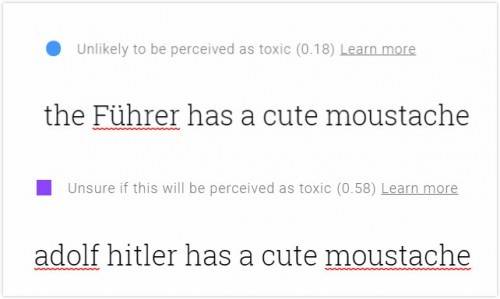
這也是Perspective會認為“吃一個中國人”(0.58)沒有“吃一個猶太人”(0.90)危險,認為 “元首的小胡子還挺可愛的”毒性很低的原因。如果把元首換成阿道夫希特勒,毒性立刻就上去了——Perspective的德語語料訓練不足,可能根本沒有。
事實上,Perspective API目前在一條評論毒性判斷上做出的這些“失準”,背后和整個社會積累已久的結構性問題有著千絲萬縷的關聯。比如,假設你用維基百科上中立但相對較為相識的美國歷史資料訓練一個人工智能,那么這個人工智能八成會堅信中國人就應該殺死或者禁止入境,而黑人理應成為下等人或者白人的奴隸。因為黑人50年前才取得在社會各層面的基本平等,而英文語境內對亞裔特別是中國人平權的討論則少之甚少。
換個更好理解的距離:如果你用微博上的數據訓練Perspective,它多半會認為開拉面店的都是壞人——事實并非如此。
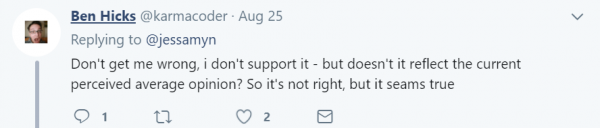
Twitter上一個用戶對此事的評論很到位:
這不正好反映了目前社會的平均意見么?它不正確,但真實。
當然,社會的結構性歧視問題并非唯一理由。Perspect的表現失常還有技術原因。
隨便做個簡單的對比測試就能大概明白這個系統的機制。前面那個納粹的例子:“我”是常見詞,“納粹”是特有名詞,它們都有各自不同的權重。但很顯然,系統認為“愛”比“恨”的毒性更低。
它無法理解整句話的意思,而是把一句話切斷成一個個單字或詞組,分別賦予它們權重,然后用一個公式計算出一個最終得分。這個公式可能在統計學上很常用,但仍足以體現出“愛”和“恨”的權重高低,也就導致了當你憎恨一個應該憎恨的事物時,系統反而認為這比你熱愛這個事物更“有毒”——這樣一個不符合邏輯的神奇結果。
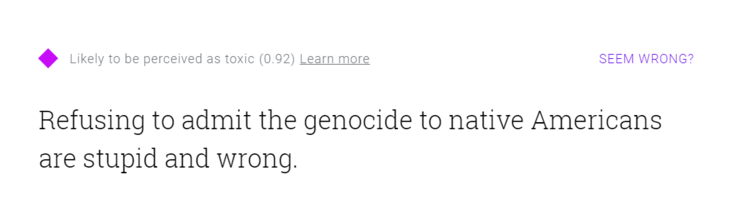
我剛做的這些測試都是短句,如果你輸入一個長句,這個技術缺陷導致的邏輯問題就更加明顯了。你可以自己到Perspective的網站上試一下:輸入一句正確的話,里面有很多貶義、體現負面情緒的詞語,比如“拒絕承認對美國土著印第安人的種族屠殺是錯誤和愚蠢的”,能得到一個相當高的結果(0.92);也可以輸入一句錯誤的話,但里面都是很平和和看起來很“科學”的字眼,比如“我認為非洲血統的人在智識上不如歐洲血統的人發達,因為后者的基因更為優異”——Perspective認為這句話“不太可能會被判定為有毒”。

本來,通過一個人工智能言論過濾系統,我們想要實現的是過濾那些歧視的、不人道的言論,促進更健康的討論。可實際的結果是它太好調戲了,而且完全沒有改變它應該改變的結構性歧視問題。
讓這個系統在網上跑著,成天品評我們在網絡上的言論健不健康、有沒有毒,結果就是那些成天無所事事在網絡上發表煽動言論的鍵盤俠被包容了,而那些敢于標明同性戀和少數族裔等異化身份,用發言來表達立場、倡導更前沿和包容觀點的人們反而成為了被打擊的對象。
這未免也太糟糕了。