

來源:新智元

【新智元導讀】圖靈獎得主、貝葉斯網絡之父Judea Pearl日前在arXiv上傳了他的最新論文,論述當前機器學習理論局限,并給出來自因果推理的7大啟發。Pearl指出,當前的機器學習系統幾乎完全以統計學或盲模型的方式運行,不能作為強AI的基礎。他認為突破口在于“因果革命”,借鑒結構性因果推理模型,能對自動化推理做出獨特貢獻。
深度學習理論研究已經引發了越來越多的關注,但是,機器學習也存在理論上的局限性。
然而,對于這個問題的關注,似乎還沒有掀起多大波瀾。
近日,圖靈獎得主、貝葉斯網絡之父Judea Pearl在arXiv上傳了他的最新論文,論述當前機器學習理論局限,并給出來自因果推理的7大啟發。
或許,你還記得 NIPS 2017上Judea Pearl 落寞的身影——在他關于機器學習理論局限的報告會上,到場的人數稀少。
 CMU教授Eric Xing的消息,Judea Pearl報告會場人跡稀少,圖片來自周志華
CMU教授Eric Xing的消息,Judea Pearl報告會場人跡稀少,圖片來自周志華報告的題目《機器學習的理論障礙》(Theoretical impediments to machine learning),正是Judea Pearl對機器學習,特別是深度學習背后理論的思考。
雖然無法親到現場,但我們可以細細閱讀Pearl這篇“因果革命”的論文。
Judea Pearl:落寞的身影與因果推理尚未激起的7大火花
Judea Pearl 曾獲得2011年的圖靈獎,獎勵他在人工智能領域的基礎性貢獻,他提出概率和因果性推理演算法,徹底改變了人工智能最初基于規則和邏輯的方向。他主要的研究領域是概率圖模型和因果推理,這是機器學習的基礎問題。圖靈獎通常頒給純理論計算機學者,或者早期建立計算機架構或框架的學者。
身為 UCLA 計算機科學系的教授,Judea Pearl曾兩次居于科學革命的中心:第一次是在 20 世紀 80 年代,他為人工智能引入了一套新的工具,叫貝葉斯網絡。第二次革命,鑒于貝葉斯網絡在計算上的優勢,Pearl 意識到簡單的圖模型和概率論(正如貝葉斯網絡中的那樣)也能用于因果關系的推理。這一發現為人工智能的發展奠定了另一個基礎,但意義遠非如此,這一能驗證因果關系的、條理性的數學方法,幾乎已經被所有科學和社會科學領域采用。
Judea Pearl 還是美國國家工程院院士,AAAI 和 IEEE Fellow,是以他兒子姓名命名的 Daniel Pearl 基金會的主席(他的兒子Daniel Pearl曾是華爾街日報記者,2002年被巴基斯坦恐怖份子綁架并斬首,為這事美國還專門拍了一部電影 ” A Mighty Heart” 。)
機器學習理論障礙與因果革命七大火花。

摘要
目前的機器學習系統幾乎完全以統計學或盲模型的方式運行,這對于其力量和性能造成了嚴格的理論上的限制。這樣的系統不能引發干預和反思,因此不能作為強AI的基礎。為了達到人類智力水平,會學習的機器需要現實模型的指導,類似于在因果推理任務中使用的模型。為了演示這些模型的重要作用,我將提出七個任務的總結,這些任務是當前機器學習系統無法實現的,并且是使用因果建模工具完成的。
科學背景
如今,如果我們審視驅動機器學習的系統,我們發現它幾乎完全以統計學的方式運行。換句話說,學習機器通過來自環境的感官輸入流參數來優化其性能。這是一個緩慢的過程,在很多方面類似于達爾文進化論的自然選擇過程。
它解釋了老鷹和蛇這樣的物種如何在數百萬年的時間里發展出高超的視覺系統。然而,它不能解釋科技超級進化的過程,例如人類能夠在幾千年的時間里建立眼鏡和望遠鏡。
人類所擁有而其他物種所缺乏的是一種心理表征,一種人類可以增加意志、想象、假設、規劃和學習來操縱生存藍圖的能力,像哈拉里(N. Harari)和米森(S. Mithen)這樣的人類學家普遍認同這一點。
在4萬年前,我們智人祖先實現全球統治的決定性因素,是他們編排環境的心理表征的能力、質疑表征的態度、并通過想象的精神付諸行動,最后假設“如果不這樣呢?”,或提出介入性探究:“如果我采取行動呢?”以及回顧性、解釋性反思:“如果我采取了不同的行動呢?”、“如果我們禁止吸煙會怎樣?” 如今,絕大多數機器學習都不具備解決這些問題的能力。
我認為解決這些問題的關鍵是給機器裝備因果推理工具來加速學習,以達到人類認知水平。這個假設在20年前的反事實信息數學化階段就已經被推測了,但今天不是這樣。
圖形和結構模型的進步使反事實計算上易于管理,從而使得模型驅動推理出一個更有前途的方向,利于建立強大的AI。在下一節中,我將使用三級層次來描述機器學習系統所面臨的障礙,這個三級層次管理因果推理中的推理。最后一節總結了如何利用現代因果推斷工具規避這些障礙。
因果關系的三大層次
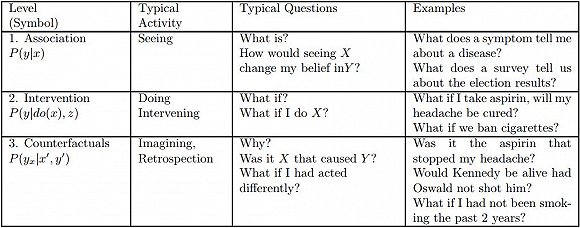 圖1:因果關系層級。i 級的問題只有在 i 級或以上級別的信息能夠獲取時才能被回答。
圖1:因果關系層級。i 級的問題只有在 i 級或以上級別的信息能夠獲取時才能被回答。因果推理的邏輯所揭示的一個非常有用的見解是,就每個類別能夠回答的問題類型而言,存在對因果信息的一個清晰的分類。
這個分類形成了一個三層的層次結構,這意味著只有當層次 j(j ≥ i)的信息可以獲得時,層次 i(i = 1,2,3)上的問題才能被回答。
圖1顯示了有3級的層次結構,以及每個級別可以回答的典型問題。這些級別分別為:①聯想(Association),②干預(Intervention),③反事實(Counterfactual)。選擇這些名字是為了強調它們的用法。我們叫第一層聯想,因為它調用了純粹的統計關系,由裸數據定義。例如,購買牙膏的顧客也更容易購買牙線;這種關聯可以使用條件期望直接從觀測數據中推斷出來。這一層的問題由于不需要因果信息,因此被放置在最底層。第二級干預比聯想要高,因為它涉及的不僅僅是看到什么,還包括改變我們所看到的。這個級別的典型問題是:如果我們將價格加倍會發生什么?這樣的問題不能單從銷售數據來回答,因為它們涉及到客戶行為的變化,這會影響新的定價。這些選擇可能與以前的漲價情況有很大不同。(除非我們精確地復制價格達到目前價值兩倍的市場條件。)最后,最頂層被稱為反事實信息(Counterfactuals),這個術語可以追溯到哲學家大衛·休謨和約翰·斯圖爾特·穆勒(John Stewart Mill),也是過去二十年來一直使用的,對計算機友好的語義。反事實類別中的一個典型問題是,“如果我采取了不同的行動會怎么辦”,因此需要追溯推理。
反事實被放在層次結構的最頂層,是因為它們包含干預和聯想的問題。如果我們有一個可以回答反事實問題的模型,我們也可以用它來回答關于干預和聯想的問題。例如,如果把價格加倍會發生什么(干預型問題)可以通過提出一個反事實的問題來回答:價格是目前價值的兩倍會發生什么?同樣,當我們可以回答干預型問題,聯想類問題也能得到回答。
相反,有了聯想問題模型,并不能回答更上層的問題,比如我們不能對那些接受過藥物治療的受試者重新進行實驗,看看他們沒有吃藥的話有會怎樣的行為。因此,層次結構是有方向性的,頂層是最強大的層次。
反事實是科學思維的基石,法律和道德推理亦是。例如,在民事法庭,被告被認為是造成傷害的罪魁禍首。如果沒有被告的行為,傷害很可能就不會發生。“如果沒有”的計算意義要求比較現實世界和沒有發生被告行為的另一個世界。
層次結構中的每一層都有一個句法簽名,用來表征被錄入的那層語句。例如,關聯層的特征是條件概率句,例如P(y | x)= p,說明:假設我們觀察到事件X = x,事件Y = y的概率等于p。在大型系統中,可以使用貝葉斯網絡或任何支持深度學習系統的神經網絡來高效計算這些證據句子。
在介入層,我們找到類型為P(y | do(x),z)的句子,它表示“事件Y = y的概率,假設我們介入并將X的值設為x,然后觀察事件Z = 。這樣的表達式可以從隨機試驗或者使用因果貝葉斯網絡(Pearl,2000,第3章)進行實驗性的估計。一個孩子通過對環境的有趣操縱(通常在一個確定性的操場上)來學習干預的效果,人工智能規劃人員通過行使他們指定的行為來獲得干預知識。無論數據有多大,都不能從被動觀察中推斷干涉表達。
最后,在反事實層面上,我們有了類型P(yx | x',y')的表達式,它代表“如果我們觀察到X是x,事件Y = y的概率就會被觀察到,基于我們實際上觀察到X是x’和Y是y'。例如,如果Joe讀完大學,他的工資就會是y。而他“只上了兩年大學”,實際工資就會是y’。”只有在我們擁有功能或結構方程模型時或具有這些模型的屬性時,才能計算出來這樣的句子。(Pearl,2000,第7章)。
這個層次結構及其所需的形式限制,解釋了為什么基于統計學的機器學習系統無法推理行動,實驗和解釋。它也告訴我們需要哪些額外的統計信息,以何種格式來支持這些推理模式。
研究人員經常感到驚訝的是,這個層次結構降低了把深度學習的成就降到了聯想的級別。與課本曲線擬合練習并列。一個反對這種比較的觀點認為,在深度學習上我們盡量減少“過擬合”,而曲線擬合的目標是盡可能最大化“擬合”。不幸的是,分隔三層的理論障礙在層次結構中告訴我們,我們的目標函數的性質并不重要。只要我們的系統優化觀測數據的某些屬性,但沒有提及數據之外的世界,我們又回到了層次結構的第一層面,這一層面有許多局限性。
因果推理模型的7大支柱:你能用因果推理模型做什么?
考慮以下 5 個問題:
給定的療法在治療某種疾病上有多有效?
是新的稅收優惠導致了銷量上升了嗎?
每年的醫療費用上升是由于肥胖癥人數增多導致的嗎?
招聘記錄可以證明雇主的性別歧視罪嗎?
我應該放棄我的工作嗎?
這些問題的一般特征是它們關心的都是原因和效應的關系,可以通過諸如導致、由于、證明和應該等詞看出這類關系。這些詞在日常語言中很常見,并且社會一直都需要這些問題的答案。然而,直到最近都沒有足夠好的科學方法對這些問題進行表達,更不用說回答這些問題了。和幾何學、機械學、光學或概率論的規律不同,原因和效應的規律曾被認為不適合應用數學方法進行分析。
但是,過去30年來,事情已發生巨大變化。一種強大而透明的數學語言已被開發出來用于處理因果關系,還有配套的把因果分析轉化為數學博弈的工具。這些工具讓我們能夠表達因果問題,然后用數據來估計答案。
我把這種轉化稱為“因果革命”(Pearl and Mackenzie, 2018, forthcoming),而導致因果革命的數理框架我將其稱之為“結構性因果模型”(Structural Causal Models,SCM)。
SCM 由三部分構成:圖模型、結構化方程、反事實和干預式邏輯
其中,圖模型作為表征知識的語言,反事實邏輯幫助表達問題,結構化方程以清晰的語義將前兩者關聯起來。
接下來我將介紹 SCM 框架的 7 項最重要的特性,并討論每項特性對自動化推理做出的獨特貢獻。
1. 編碼因果假設——透明度和可測試性
一旦我們認真對待透明度(transparency)和可測試性(testability)的要求,用一種緊湊的、可用的形式來編碼假設的任務并不是一件簡單的事情。透明度使分析人員能夠辨別所編碼的假設是否合理(基于科學依據),或者是否有必要進行額外的假設。可測試性允許我們(無論是分析師還是機器)能夠確定所編碼的假設是否與可用數據兼容,如果不兼容,則識別那些需要修復的假設。
圖模型(graphical models)的進步使緊湊編碼變得可行。它們的透明度來源于這樣一個事實:所有假設都是用圖形編碼的,這與研究人員對領域中因果關系的理解方式是一致的;不需要對反事實或統計依賴性的判斷,因為這些可以從圖的結構中讀出。可測試性是通過一個稱為d-separation的圖形標準來促進的,它提供了原因和概率之間的基本聯系。它告訴我們,對于模型中任何給定的路徑模式,哪些依賴模式是數據中應該存在的(Pearl, 1988)。
2. Do-calculus和控制混雜
混雜(confounding),或者說出現兩個或多個變量的未被觀察到的因素,長期以來被認為是從數據中得出因果推斷的主要障礙。通過一種稱為“back-door”的圖形標準可以“解混雜”(deconfound)。選擇一組合適的變量來控制混雜的任務已經被簡化成一個簡單的“roadblocks”問題,可以用一個簡單的算法解決(Pearl, 1993)。
對于那些“back-door”標準不成立的模型,有一個符號引擎叫做“do-calculus”,它能預測任何可行情況下策略干預的效果,當預測不能用特定的假設來確定時,會以失敗退出(Pearl, 1995; Tian and Pearl, 2002; Shpitser and Pearl, 2008)。
3. 反事實的算法化
反事實分析處理的是特定個體的行為,根據一組不同的特征來確定。例如,假設Joe的薪資為Y = y,并且他上了X = x年大學,那么Joe的薪資是多少呢?那么假如Joe再上一年大學,他的薪資會是多少?
因果革命的一項成就是,在圖形表示中將反事實推理形式化,圖形表示是研究人員用來編碼科學知識的一種表現形式。每個結構方程模型都決定了每個反事實語句的真值。因此,我們可以通過分析來判斷句子的概率是否可以通過實驗或觀察研究來確定,或通過這兩者的組合來估算[Balke and Pearl, 1994; Pearl, 2000, Chapter 7]。
在有關因果的論述中,人們特別感興趣的是關于“效果的原因”(causes of effects)的反事實問題(和“原因的效果”相對)。例如,Joe去游泳是Joe死亡的必要(或充分)原因(Pearl, 2015a; Halpern and Pearl, 2005)。
4. 調解分析和直接、間接效應的評估
調解分析(mediation analysis)關注的是將變化從原因傳遞到效果的機制。對中間機制的檢測是生成解釋的基礎,且必須應用反事實邏輯幫助進行檢測。反事實的圖形表示使我們能夠定義直接和間接效應,并確定這些效應可以從數據或實驗估計的條件(Robins and Greenland, 1992; Pearl, 2001; VanderWeele, 2015)。由這個分析可以回答的典型問題是:X對Y的影響有多少是由變量Z導致的。
5. 外部有效性和樣本選擇偏差
所有實驗研究的有效性都受到實驗和實現設置之間差異的影響。當環境條件發生變化時,我們沒法期待在某個環境中訓練的機器還能夠表現良好,除非這些變化是局部的、可確定的。這個問題及其各種表現形式都已經被機器學習研究者認可,諸如“領域適應”、“遷移學習”、“終身學習”和“可解釋的人工智能”等等,這些只是研究人員和資助機構研究的一些子任務,試圖緩解穩健性(robustness)的普遍問題。
不幸的是,穩健性的問題需要環境的因果模型,并且不能在關聯級別上進行處理,在這個級別上,大多數補救措施都已經嘗試過了。關聯(association)不足以確定所發生的變化所影響的機制。我們前面討論的 do-calculus為克服環境變化帶來的偏見提供了一種完整的方法,它既可用于重新調整學習政策以規避環境變化,也可用于控制非典型樣本的偏差(Bareinboim and Pearl, 2016)。
6. 數據丟失
數據丟失的問題困擾著實驗科學的每一分支。例如,受訪者沒有回答全問卷所有項目,傳感器因環境條件變化而失靈,患者經常因為未知的原因退出臨床研究。對于這個問題,大量的文獻致力于統計分析的盲模型范式(model-blind paradigm),因此,這些研究嚴重局限于數據丟失隨機發生的情況,也就是說,與模型中其他變量的值無關。使用丟失過程(missingness process)的因果模型,我們現在可以把因果關系和概率關系從不完整的數據中恢復出來,并且只要條件滿足,就可以得到對所需關系的一致估計(Mohan and Pearl, 2017)。
7. 因果發現
前面描述的d-separation標準使我們能夠檢測和列舉給定的因果模型的可測試推斷。這為利用不精確的假設和數據兼容的模型集合進行推理提供了可能,并且可以緊湊地表示這個集合。系統的搜索已經被開發出來,在某些情況下,可以將一組兼容模型的集合修剪到可以直接從該集合中評估因果問題的程度(Spirtes et al., 2000; Pearl, 2000; Peters et al., 2017)。
結論
哲學家Stephen Toulmin認為,基于模型與盲模型的二分法是理解巴比倫與古希臘科學之間競爭的關鍵。根據Toulmin的說法,巴比倫天文學家是黑箱預測的高手,在準確性和一致性方面遠遠超過了古希臘人(Toulmin,1961,pp.27-30)。然而科學卻青睞希臘天文學家的創造性思辨戰略,這種戰略和形而上學的形象一樣很狂野:充滿火焰的圓形管,可以看見天火的小洞,還有騎在龜背上的半球形地球。然而,這種狂野的建模策略,顛覆了Eratosthenes(公元前276 - 194年)在古代世界最有創造性的實驗之一,并測量了地球的半徑。這絕對不會發生在巴比倫。
回到強人工智能,我們已經看到,對可執行的認知任務來說,盲模型的方法有內在限制。我們描述了其中的一些任務,并展示了如何在SCM框架中完成這些任務,以及對于執行這些任務,為什么基于模型的方法是必不可少的。我們的總體結論是,人類的AI不能單純地從盲模型的學習機器中出現,它需要數據和模型的共生協作。
數據科學只不過是一門科學而已,因為它有助于解釋數據:這是一種二體問題,將數據與現實聯系起來。不管數據有多大,如何被靈巧應用,數據本身并不是一門科學。

“掌”握科技鮮聞 (微信搜索techsina或掃描左側二維碼關注)










